publications
2024
-
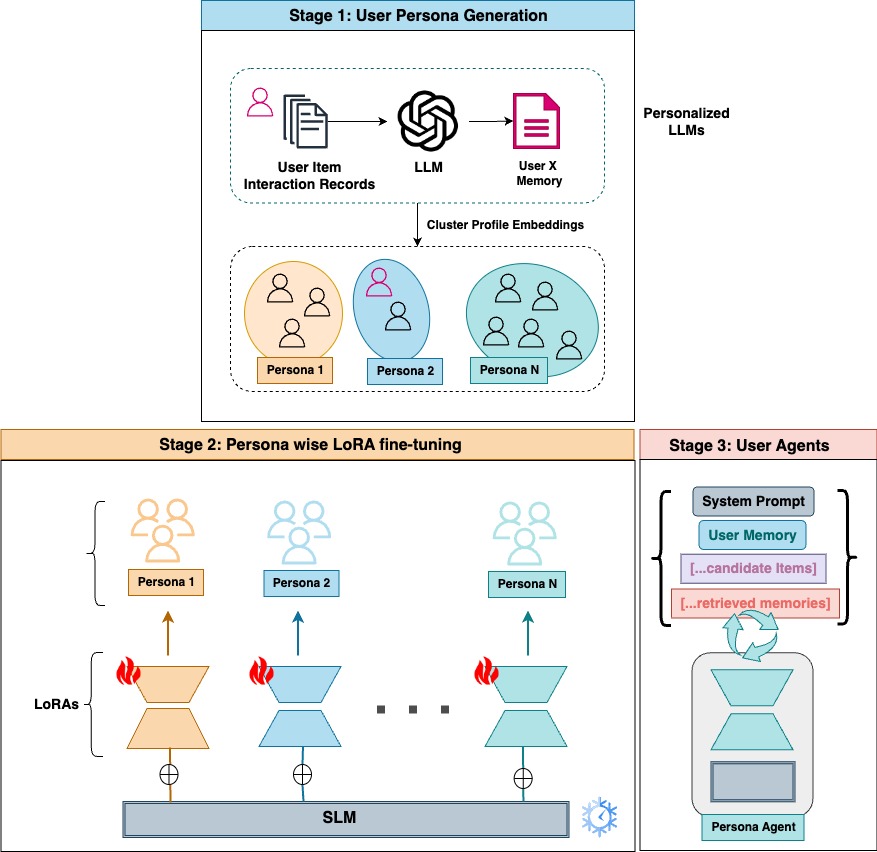 Personas within Parameters: Fine-Tuning Small Language Models with Low-Rank Adapters to Mimic User BehaviorsHimanshu Thakur, Eshani Agrawal, and Smruthi MukundNeural Information Processing Systems (AFM Workshop), 2024
Personas within Parameters: Fine-Tuning Small Language Models with Low-Rank Adapters to Mimic User BehaviorsHimanshu Thakur, Eshani Agrawal, and Smruthi MukundNeural Information Processing Systems (AFM Workshop), 2024A long-standing challenge in developing accurate recommendation models is simulating user behavior, mainly due to the complex and stochastic nature of user interactions. Towards this, one promising line of work has been the use of Large Language Models (LLMs) for simulating user behavior. However, aligning these general-purpose large pre-trained models with user preferences necessitates: (i) effectively and continously parsing large-scale tabular user-item interaction data, (ii) overcoming pre-training-induced inductive biases to accurately learn user specific knowledge, and (iii) achieving the former two at scale for millions of users. While most previous works have focused on complex methods to prompt an LLM or fine-tune it on tabular interaction datasets, our approach shifts the focus to extracting robust textual user representations using a frozen LLM and simulating cost-effective, resource-efficient user agents powered by fine-tuned Small Language Models (SLMs). Further, we showcase a method for training multiple low-rank adapters for groups of users or persona, striking an optimal balance between scalability and performance of user behavior agents. Our experiments provide compelling empirical evidence of the efficacy of our methods, demonstrating that user agents developed using our approach have the potential to bridge the gap between offline metrics and real-world performance of recommender systems.
@article{thakurpersonas, title = {Personas within Parameters: Fine-Tuning Small Language Models with Low-Rank Adapters to Mimic User Behaviors}, author = {Thakur, Himanshu and Agrawal, Eshani and Mukund, Smruthi}, journal = {Neural Information Processing Systems (AFM Workshop)}, year = {2024}, primaryclass = {cs.CL}, }

2023
-
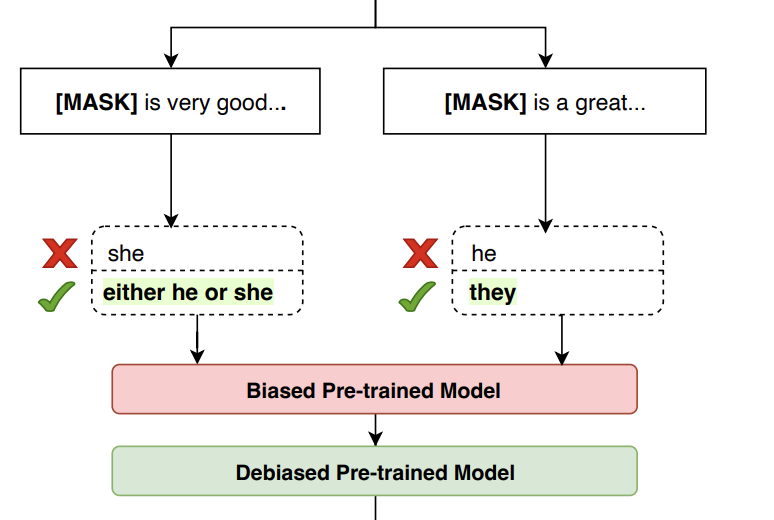 Language Models Get a Gender Makeover: Mitigating Gender Bias with Few-Shot Data InterventionsHimanshu Thakur, Atishay Jain, Praneetha Vaddamanu, Paul Pu Liang, and Louis-Philippe MorencyAssociation for Computational Linguistics, 2023
Language Models Get a Gender Makeover: Mitigating Gender Bias with Few-Shot Data InterventionsHimanshu Thakur, Atishay Jain, Praneetha Vaddamanu, Paul Pu Liang, and Louis-Philippe MorencyAssociation for Computational Linguistics, 2023Societal biases present in pre-trained large language models are a critical issue as these models have been shown to propagate biases in countless downstream applications, rendering them unfair towards specific groups of people. Since large-scale retraining of these models from scratch is both time and compute-expensive, a variety of approaches have been previously proposed that de-bias a pre-trained model. While the majority of current state-of-the-art debiasing methods focus on changes to the training regime, in this paper, we propose data intervention strategies as a powerful yet simple technique to reduce gender bias in pre-trained models. Specifically, we empirically show that by fine-tuning a pre-trained model on only 10 de-biased (intervened) training examples, the tendency to favor any gender is significantly reduced. Since our proposed method only needs a few training examples, our few-shot debiasing approach is highly feasible and practical. Through extensive experimentation, we show that our debiasing technique performs better than competitive state-of-the-art baselines with minimal loss in language modeling ability.
@article{thakur2023language, title = {Language Models Get a Gender Makeover: Mitigating Gender Bias with Few-Shot Data Interventions}, author = {Thakur, Himanshu and Jain, Atishay and Vaddamanu, Praneetha and Liang, Paul Pu and Morency, Louis-Philippe}, journal = {Association for Computational Linguistics}, year = {2023}, eprint = {2306.04597}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, } -
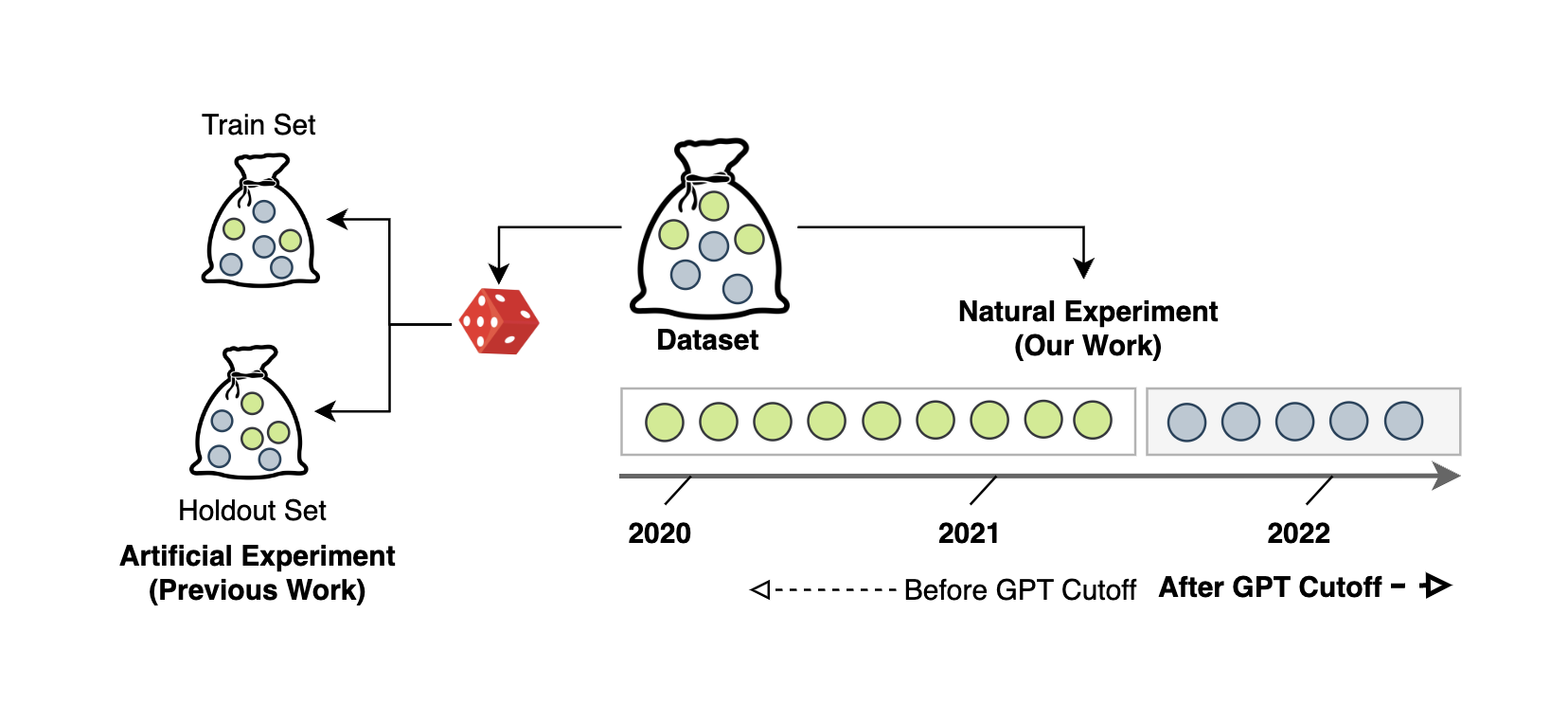 Data Contamination Through the Lens of TimeManley Roberts, Himanshu Thakur, Christine Herlihy, Colin White, and Samuel DooleyNeural Information Processing Systems (ICBINB Workshop), 2023
Data Contamination Through the Lens of TimeManley Roberts, Himanshu Thakur, Christine Herlihy, Colin White, and Samuel DooleyNeural Information Processing Systems (ICBINB Workshop), 2023Recent claims about the impressive abilities of large language models (LLMs) are often supported by evaluating publicly available benchmarks. Since LLMs train on wide swaths of the internet, this practice raises concerns of data contamination, i.e., evaluating on examples that are explicitly or implicitly included in the training data. Data contamination remains notoriously challenging to measure and mitigate, even with partial attempts like controlled experimentation of training data, canary strings, or embedding similarities. In this work, we conduct the first thorough longitudinal analysis of data contamination in LLMs by using the natural experiment of training cutoffs in GPT models to look at benchmarks released over time. Specifically, we consider two code/mathematical problem-solving datasets, Codeforces and Project Euler, and find statistically significant trends among LLM pass rate vs. GitHub popularity and release date that provide strong evidence of contamination. By open-sourcing our dataset, raw results, and evaluation framework, our work paves the way for rigorous analyses of data contamination in modern models. We conclude with a discussion of best practices and future steps for publicly releasing benchmarks in the age of LLMs that train on webscale data.
@article{roberts2023data, title = {Data Contamination Through the Lens of Time}, author = {Roberts, Manley and Thakur, Himanshu and Herlihy, Christine and White, Colin and Dooley, Samuel}, journal = {Neural Information Processing Systems (ICBINB Workshop)}, year = {2023}, eprint = {2310.10628}, archiveprefix = {arXiv}, primaryclass = {cs.CL}, } -
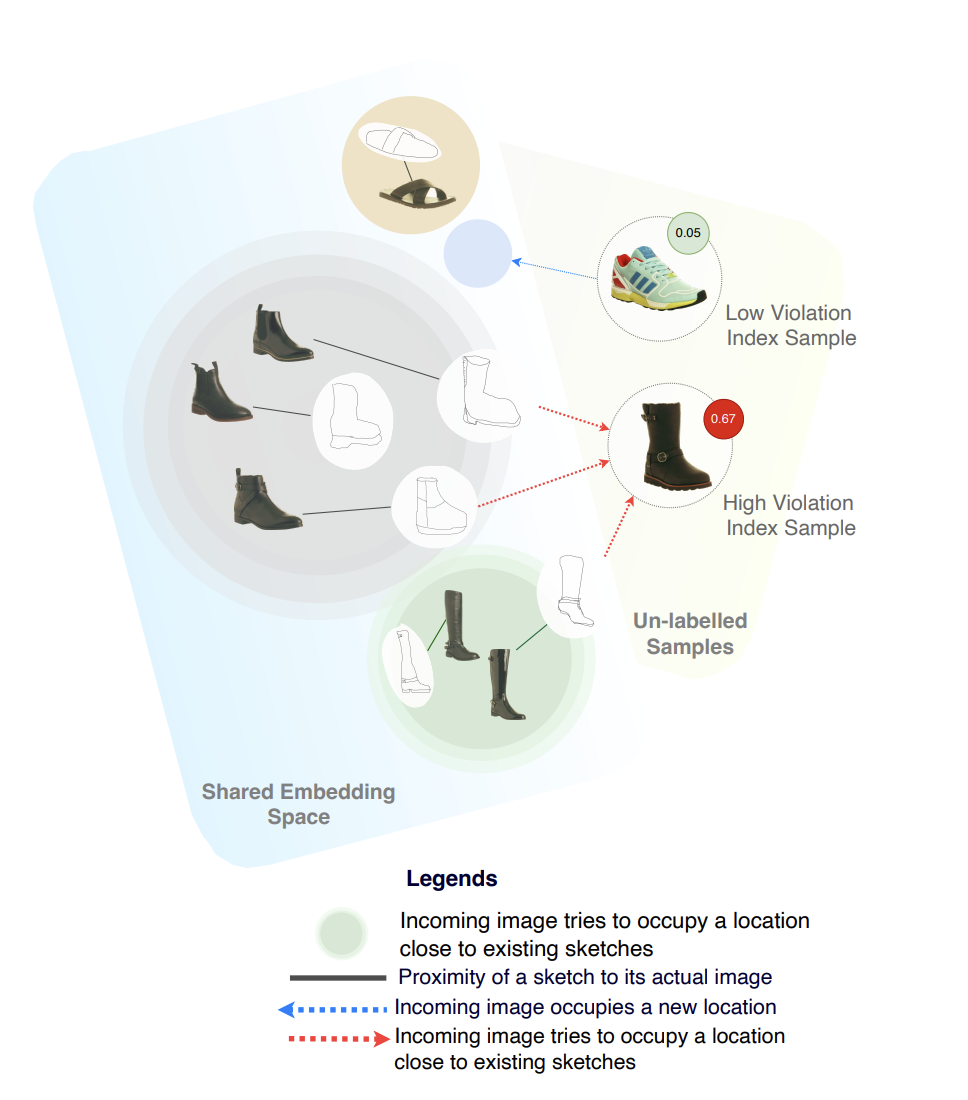 Active Learning for Fine-Grained Sketch-Based Image RetrievalHimanshu Thakur, and Soumitri ChattopadhyayBritish Machine Vision Conference, 2023
Active Learning for Fine-Grained Sketch-Based Image RetrievalHimanshu Thakur, and Soumitri ChattopadhyayBritish Machine Vision Conference, 2023The ability to retrieve a photo by mere free-hand sketching highlights the immense potential of Fine-grained sketch-based image retrieval (FG-SBIR). However, its rapid practical adoption, as well as scalability, is limited by the expense of acquiring faithful sketches for easily available photo counterparts. A solution to this problem is Active Learning, which could minimise the need for labeled sketches while maximising performance. Despite extensive studies in the field, there exists no work that utilises it for reducing sketching effort in FG-SBIR tasks. To this end, we propose a novel active learning sampling technique that drastically minimises the need for drawing photo sketches. Our proposed approach tackles the trade-off between uncertainty and diversity by utilising the relationship between the existing photo-sketch pair to a photo that does not have its sketch and augmenting this relation with its intermediate representations. Since our approach relies only on the underlying data distribution, it is agnostic of the modelling approach and hence is applicable to other cross-modal instance-level retrieval tasks as well. With experimentation over two publicly available fine-grained SBIR datasets ChairV2 and ShoeV2, we validate our approach and reveal its superiority over adapted baselines
@article{thakur2023active, title = {Active Learning for Fine-Grained Sketch-Based Image Retrieval}, author = {Thakur, Himanshu and Chattopadhyay, Soumitri}, journal = {British Machine Vision Conference}, year = {2023}, eprint = {2309.08743}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, }



2022
-
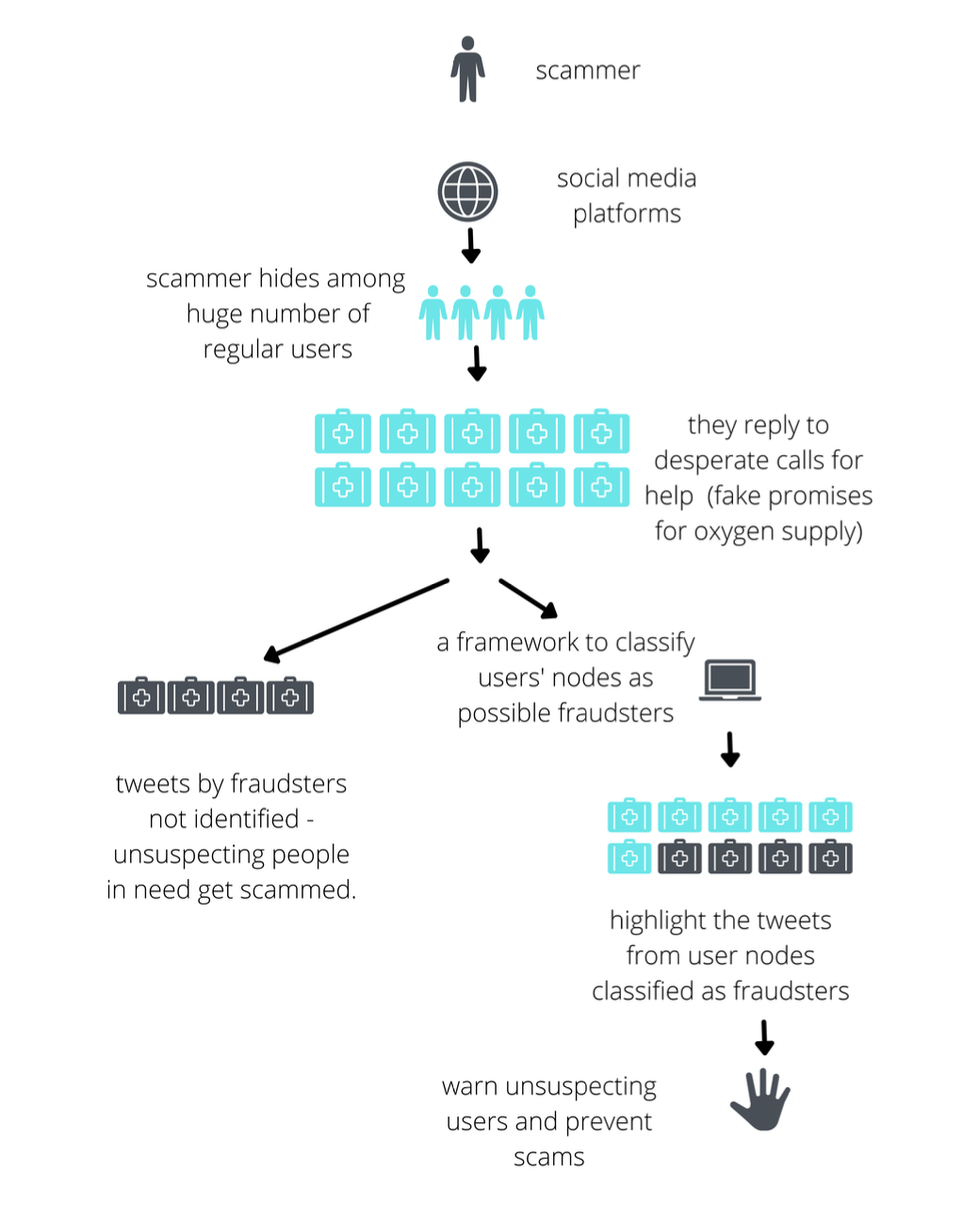 Safeguarding People against Social Media Frauds during the COVID-19 Oxygen Supply Crisis in IndiaAAYUSH KAPUR, Himanshu Thakur, and Harsh KumarNeural Information Processing Systems (ML4D Workshop), Oct 2022
Safeguarding People against Social Media Frauds during the COVID-19 Oxygen Supply Crisis in IndiaAAYUSH KAPUR, Himanshu Thakur, and Harsh KumarNeural Information Processing Systems (ML4D Workshop), Oct 2022@article{kapur_thakur_kumar_2022, title = {Safeguarding People against Social Media Frauds during the COVID-19 Oxygen Supply Crisis in India}, url = {osf.io/58sry}, doi = {10.31219/osf.io/58sry}, journal = {Neural Information Processing Systems (ML4D Workshop)}, publisher = {OSF Preprints}, author = {KAPUR, AAYUSH and Thakur, Himanshu and Kumar, Harsh}, year = {2022}, month = oct, }

